

22·
3 months agoTIL LibreOffice has socials! One of these days I should look into joining Mastodon
TIL LibreOffice has socials! One of these days I should look into joining Mastodon

The author probably is using the historic definition:
… advanced computer technology enthusiast (both hardware and software) and adherent of programming subculture
Yeah, I see what you mean. That makes sense. After reading through some common OSS licenses, I can see the difference between licenses that require you not to modify the license notification, versus software that explicitly forbids certain changes. But, given how little funding OSS projects get, I’m not bothered by the idea that they want to make sure people financially contribute to the original creators. After all, if someone does fork it and do a better job, they could easily just put their own donate button higher up above the original one.
What part of the FUTO keyboard license isn’t open source? It looks like most of what it says is in line with the kind of stuff you find in the GPL, MIT, BSD licenses. Is the non-commercial restriction the reason people say it’s “not open source”?
Yeah, on the one hand I agree with your sentiment, but on the other hand it’s not that simple. Nothing in the government ever moves quick, and the IRS loves to give you plenty of time to dig your own grave as deep as you want.
The article above goes into more analysis about this situation, and includes a great quote that rings to what I previously mentioned:
“Here’s a useful trick for highly affluent readers who are desperate to avoid the exit tax: Live wherever you want, but don’t renounce citizenship. The constructive sale of assets and resulting taxable gains probably aren’t worth the trouble. Above all, don’t paint yourself into a corner by renouncing your citizenship and then calculating what your exit tax will be. The benefit of performing the calculation first is that it can influence your decision as to whether renunciation is worth it.”
Right, it’s not about the IRS smelling millions, it’s about him wiring crypto to businesses he owned and him not reporting it on his taxes during expatriation. It’s all in the indictment papers. Pretty bog-standard tax fraud, nothing really out of the ordinary or exciting.
It looks like he could’ve dodged this by not making a lot of the decisions he made. It was definitely a bad move for him to wire crypto to bank accounts tied to businesses. It also looks like this became a big issue when he decided to go through expatriation, which required him to report and pay taxes for the capital gains. A law firm allegedly told him to “pretend” that he sold almost everything, leading him to not report any Bitcoin for both his assets and taxes, which seems like the ‘law firm’ was literally telling him to do fraud; he still went through with that despite how fishy it sounds? Can’t help but feel like any legal firm telling you to “pretend” anything is a scam… It seems like he brought a lot of this on himself, but it also shows how deeply the IRS will dig their claws into you if they smell a couple million dollars.
Indictment PDF: https://www.justice.gov/opa/media/1350116/dl?inline
https://www.justice.gov/opa/pr/early-bitcoin-investor-charged-tax-fraud
Yes, assuming video content is stored across decentralized PDS instances
I tested it with “cat” and it blocks me from seeing things I’ve reposted with the word “cat” in it, so yeah it might! :)
A quick scroll of his account on Bluesky ( https://bsky.app/profile/urlyman.mastodon.social.ap.brid.gy ) makes it pretty clear why his Discover sucks. The algorithm on Bluesky sorta works like a mirror, you get out what you put in. My feed is all art posts and wholesome memes because I follow artists, creators, and comic pages, so it sounds like he’s trained his algorithm to be full of political complaining and toxic people like him. He should probably look into the Mute Words feature and start blocking stuff he thinks is toxic!
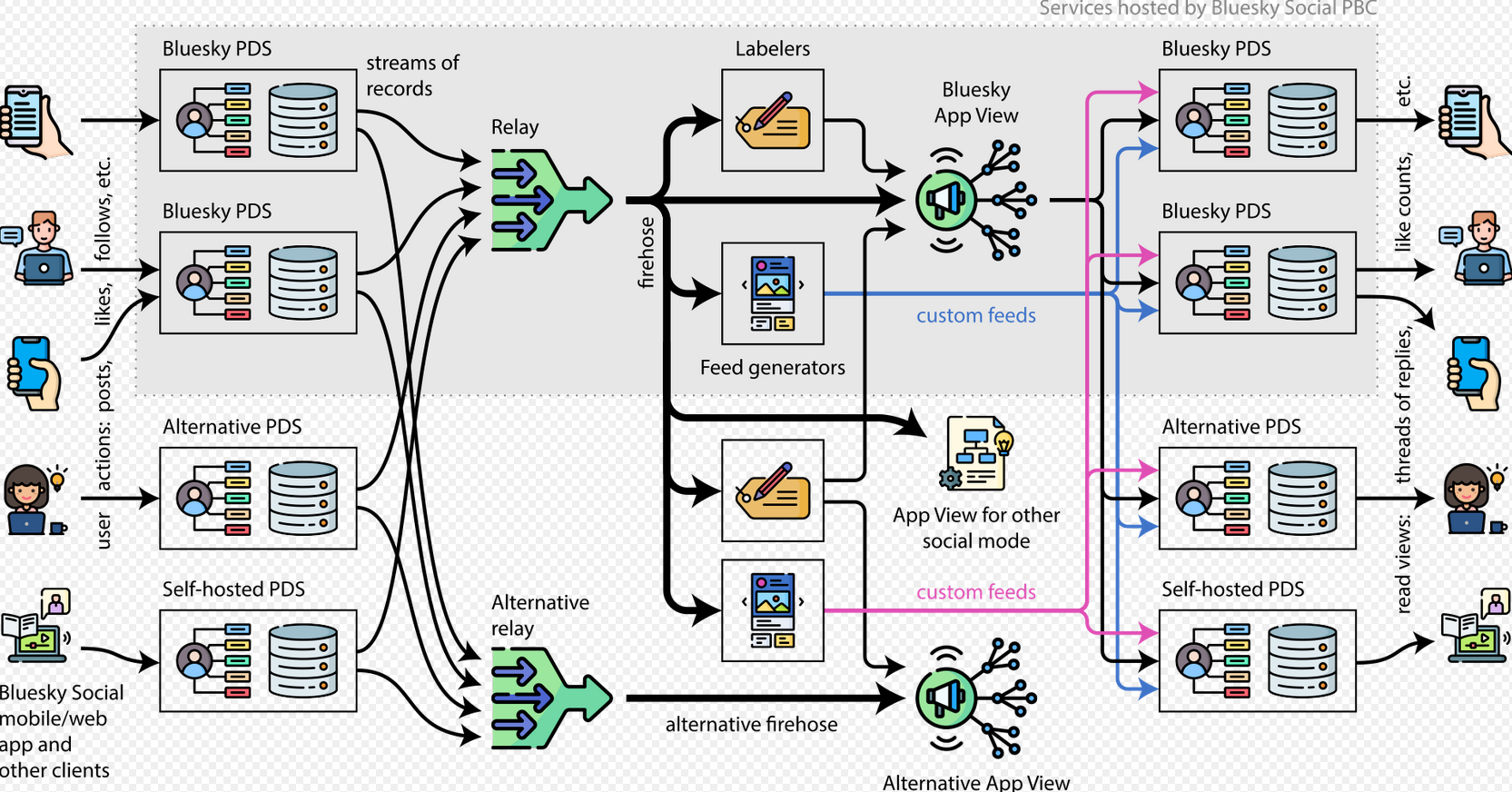
Bluesky is the first app built on the ATProtocol, its protocol for federation, sort of like how Mastodon was among the first to use ActivityPub after the overcomplexity of OStatus. The ATProtocol is a few years younger than ActivityPub, so its landscape isn’t fleshed out yet. Currently Bluesky caters more towards creators, artists, and social togetherness, whereas ActivityPub tends to lean harder into attracting techies. Both protocols can be run as independent instances, but most people are still using bsky.social for now until more instances pop up and federate together. The process for hosting a Bluesky instance is still undergoing development, but all features of it have been opened up. There exist multiple bridge systems that can interweave ActivityPub with ATProto.
https://github.com/bluesky-social/pds
https://whtwnd.com/bnewbold.net/entries/Notes on Running a Full-Network atproto Relay (July 2024)
You can run your own relays, the obstacle is that each relay takes up many terabytes. But it’s fully open.
https://github.com/bluesky-social/pds
https://whtwnd.com/bnewbold.net/entries/Notes on Running a Full-Network atproto Relay (July 2024)
https://news.ycombinator.com/item?id=42094369
https://docs.bsky.app/docs/advanced-guides/firehose
https://docs.bsky.app/docs/advanced-guides/federation-architecture#relay
Mobile games are designed like junk-food: take it out, eat some junk, then put it away to go do something else, throw away the bag or seal it for a quick snack later. Normal games are designed like a full meal: sit down somewhere with good atmosphere, nutritious, good conversation, get full and go home with plenty of leftovers and good memories
TinyLLM on a separate computer with 64GB RAM and a 12-core AMD Ryzen 5 5500GT, using the rocket-3b.Q5_K_M.gguf model, runs very quickly. Most of the RAM is used up by other programs I run on it, the LLM doesn’t take the lion’s share. I used to self host on just my laptop (5+ year old Thinkpad with upgraded RAM) and it ran OK with a few models but after a few months saved up for building a rig just for that kind of stuff to improve performance. All CPU, not using GPU, even if it would be faster, since I was curious if CPU-only would be usable, which it is. I also use the LLama-2 7b model or the 13b version, the 7b model ran slow on my laptop but runs at a decent speed on a larger rig. The less billions of parameters, the more goofy they get. Rocket-3b is great for quickly getting an idea of things, not great for copy-pasters. LLama 7b or 13b is a little better for handing you almost-exactly-correct answers for things. I think those models are meant for programming, but sometimes I ask them general life questions or vent to them and they receive it well and offer OK advice. I hope this info is helpful :)






As nice as this would be, it’s not very likely… Licenses are usually limp suggestions from the perspective of companies with billions of dollars. AI companies train on millions of copyrighted materials, both literature and art, without any express permission from the authors or artists, and with essentially no recourse or compensation to the authors. You could append a ‘no AI training’ clause to an existing license like the MIT license, but the impact that will have will mostly be brief personal satisfaction and won’t change what the AI companies do. It’s genuinely more useful to keep code proprietary to prevent it from being used to train AI models.